Simplify Text Chunking for Vector Embeddings
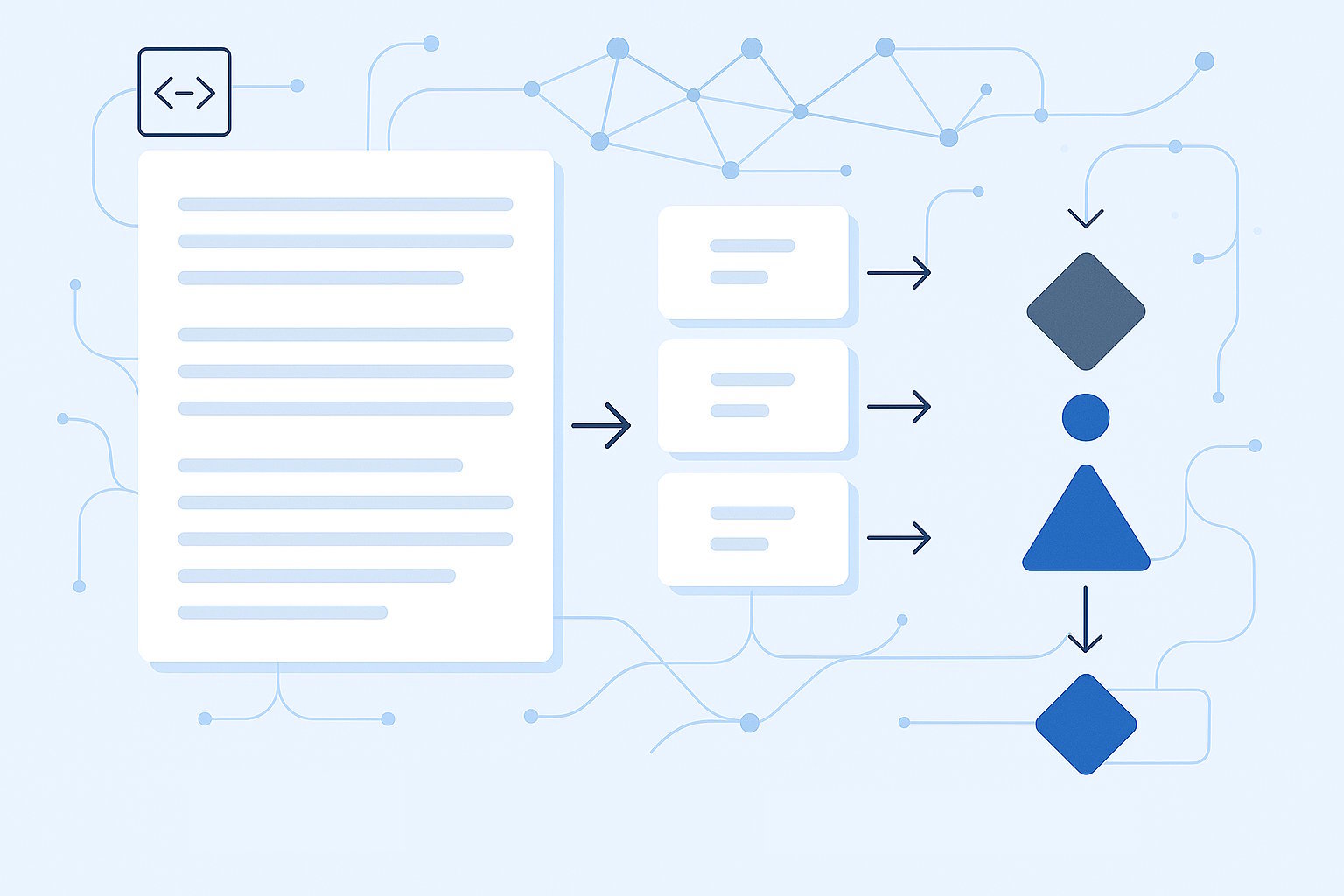
Text chunking is crucial when working with vector embedding models, no matter where you host them. In my previous article, Vector Embedding for Long Documents, I explored how to combine multiple vectors into one. In this post, I’ll share sample code for how to do both chunking long text and combining multiple vectors into one. With the help of Denomica.OpenAI.Extensions, which is published on NuGet, this task is a breeze. This library is built specifically for use with Azure AI Foundry and designed to be both simple and extensible. The source code for this library is also available on Github. If you like this library and find it useful, I would appreciate if you would give the repository a star.
Text Chunking and Vector Embedding
Before we dive into code, let’s have a few words about why text chunking is so important when dealing with vector embeddings. All embedding models, or at least the ones I know of, have limits on how much text they can process. So, if your text exceeds this limit, you have to chunk up your text into smaller parts.
There are a few problems that the Denomica.OpenAI.Extensions library tries to address, in current or future versions.
- Embedding model limits are measured in tokens – not characters, words, or sentences. While tokens can be tricky to estimate, in normal English text a token typically averages around four characters.
- Because of these limits, you have to chunk up your text into smaller pieces so that you don’t exceed the limits.
- After chunking up text and generating an embedding for each vector, you typically want to aggregate them into one embedding representing your original text.
The chapters below describe in more detail how Denomica.OpenAI.Extensions addresses these problems.
Text Chunking in Denomica.OpenAI.Extensions
The Denomica.OpenAI.Extensions library provides a mechanism that allows you to register a chunking service that will take care of the chunking. When you use the EmbeddingProvider class to generate embeddings, the registered chunking service is automatically used to chunk up your text. There is one chunking service provided by the library, the LineChunkingService. This service chunks up the text line by line. One chunk can contain several lines of text as long as it does not exceed the maximum configured size of a chunk.
The code below shows how you can register a chunking service and how to use the EmbeddingProvider to generate embeddings.
using Denomica.OpenAI.Extensions.Embeddings;
using Denomica.OpenAI.Extensions.Text;
using Microsoft.Extensions.DependencyInjection;
var provider = new ServiceCollection()
.AddOpenAIExtensions()
.WithEmbeddingModel((opt, sp) =>
{
opt.Endpoint = $"https://[Your Azure AI Foundry hub name].openai.azure.com";
opt.ApiKey = "[Your API key goes here]";
opt.Name = "[The name of the embedding model deployment]";
})
.WithChunkingService<LineChunkingService>()
.Services.BuildServiceProvider();
var embeddingProvider = provider.GetRequiredService<EmbeddingProvider>();
var embedding = await embeddingProvider.GenerateEmbeddingAsync("Hello World!");
Configuring the LineChunkingService
The LineChunkingService chunks up text line by line into chunks that do not exceed the configured length in characters. Most of the embedding models in Azure AI Foundry have a token limit around 8000 tokens. A rough estimate is that one token evaluates to about 4 characters. That would mean that the maximum length of text that can be used for embedding is around 32 000 characters.
The LineChunkingService uses a default limit of 25 000 characters in order to be safely under the 8000 token limit. Of course, this is not the best solution in every case. You can configure this limit to a value that better suits your needs. The code below shows you how to do this.
var provider = new ServiceCollection()
.AddOpenAIExtensions()
.WithEmbeddingModel((opt, sp) =>
{
// Configure your embedding model here.
})
.WithChunkingService(sp =>
{
return new LineChunkingService { MaxChunkSize = 10000 };
})
.Services
.BuildServiceProvider();
Create Your Own Chunking Service
The Denomica.OpenAI.Extensions library also allows you to write your own chunking service, and register that to be used by EmbeddingProvider. Below is a simple version of a custom chunking service that you can then develop into your own text chunking service.
using Denomica.OpenAI.Extensions.Text;
using System.IO;
public class MyCustomChunkingService : IChunkingService
{
public int MaxChunkSize { get; set; } = 8000;
public virtual async IAsyncEnumerable<string> GetChunksAsync(Stream input)
{
string inputString;
using(var reader = new StreamReader(input))
{
inputString = await reader.ReadToEndAsync();
}
}
public async IAsyncEnumerable<string> GetChunksAsync(string input)
{
// Do your chunking logic here.
}
}
When you have implemented your chunking service, you register it like shown below.
var provider = new ServiceCollection()
.AddOpenAIExtensions()
.WithChunkingService<MyCustomChunkingService>()
.Services
.BuildServiceProvider();
Aggregating Multiple Vector Embeddings
The EmbeddingProvider automatically uses the configured chunking service to chunk up text. If the chunking service produces more than one chunk, there will also be more than one embeddings generated. It will also automatically use the registered embedding aggregation service to aggregate multiple embeddings into one before returning. If no aggregation service is registered, the default WeightedAverageAggregationService is used.
The WeightedAverageAggregationService uses a weighted average approach to aggregate multiple embeddings into one. This aggregation service uses the total amount of tokens used to produce the embedding as weight. The more tokens consumed, the longer the text typically is, or is otherwise more significant in relation to other embeddings.
Create Your Own Aggregation Service
You can also create your own custom aggregation service and register that to be used instead of the default. The code below shows how to implement your custom aggregation service.
using System.Collections.Generic;
using System.Threading.Tasks;
using Denomica.OpenAI.Extensions.Embeddings;
public class MyCustomAggregationService : IEmbeddingAggregationService
{
public Task<EmbeddingResponse?> AggregateAsync(IEnumerable<EmbeddingResponse>? embeddings)
{
// Implement your aggregation logic here.
return null;
}
}
When you have implemented your custom aggregation service, you can register it like shown below.
var provider = new ServiceCollection()
.AddOpenAIExtensions()
.WithEmbeddingModel((opt, sp) =>
{
})
.WithEmbeddingAggregationService<MyCustomAggregationService>()
.Services
.BuildServiceProvider();
Wrapping Up: Smarter Embeddings with Less Effort
Working with long input text and vector embedding models doesn’t have to be complicated. Denomica.OpenAI.Extensions provides a clean and extensible way to handle both text chunking and embedding aggregation – without writing boilerplate code or reinventing the wheel. Whether you’re using the default weighted average logic or plugging in your own services, the library is designed to fit naturally into your AI-driven .NET applications. Give it a try via NuGet, and feel free to explore, extend, or contribute.

0 Comments