Cosmos DB Vector Search – An Introduction

Applications powered by Generative AI are becoming more and more popular. Often these applications employ some kind of RAG (Retrieval-Augmented Generation) solution patterns. For RAG powered applications, the Cosmos DB Vector Search feature can be very useful. In this article I’ll describe this feature in more detail. This will give you better information to base your decisions on when deciding whether you could leverage this in your applications.
You might also want to have a look at another article where I compare Cosmos DB vector search with traditional indexing.
Understanding Vector Embeddings
A vector embedding is basically an array of floating-point numbers. What is also characteristic for embeddings is that they are fixed-sized. It does not matter how long or complex the input is. The vector embedding generated by one model always has the same number of dimensions. However, some models allow you to specify the number of dimensions you want in the vector embedding.
But what makes vector embeddings so useful is that they encapsulate the semantic context of the input. The closer a vector is to another vector, the more similar the inputs represented by the vectors are. You can think of a vector as a path. If your input talks about bananas, the resulting vector or “path” passes close to the “area” where fruits are discussed. If your input talks about cars, then the path goes by the “area” where vehicles are discussed. This analogy helped me to get my mind around the concept of vector embeddings. This document from Microsoft Learn about Vector Embeddings in Cosmos DB can also give you a better idea of how vector embeddings are designed to work.
You use Cosmos DB Vector Search to find content similar to something else. To find similar content you first generate a vector (“query vector”) for the data you want to find similar content to. Then you search for content with vectors that are closest to your query vector. You must generate the query vector in the same way as you generated the vectors for your content. This includes also using the same embedding model. If you decide to switch model, you need to regenerate the vectors that you have stored.
Vector Embeddings Can Be Language Agnostic
Since embedding models capture the semantic context of the input rather than the actual content, they can also be language agnostic. However, this is not always the case. Some models might be better on capturing semantics regardless of the language than others. If you have an embedding model that is truly language agnostic, the vectors they produce for input with the same meaning but in different languages, should be very similar. This can be helpful if your content is in another language that you use when creating your query vectors. If this is an important requirement for you, you need to do your due diligence and make sure that you pick an embedding model that can properly handle different languages.
Setting up Cosmos DB Vector Search
The first thing you have to do to turn on Cosmos DB Vector Search is to enable that feature on your Cosmos DB account. There are two steps to enable Cosmos DB Vector Search:
- Turn on the feature for your Cosmos DB Account
- Create a container with a vector policy
Note! Once you have turned that feature on, you cannot turn it off again. It is a one-way street, so remember this before you go on turning on this feature on all your Cosmos DB accounts.
You can turn this feature on in the Azure portal. Navigate to your Cosmos DB account and select Settings/Features from the menu. Then turn on the Vector Search for NoSQL API feature.
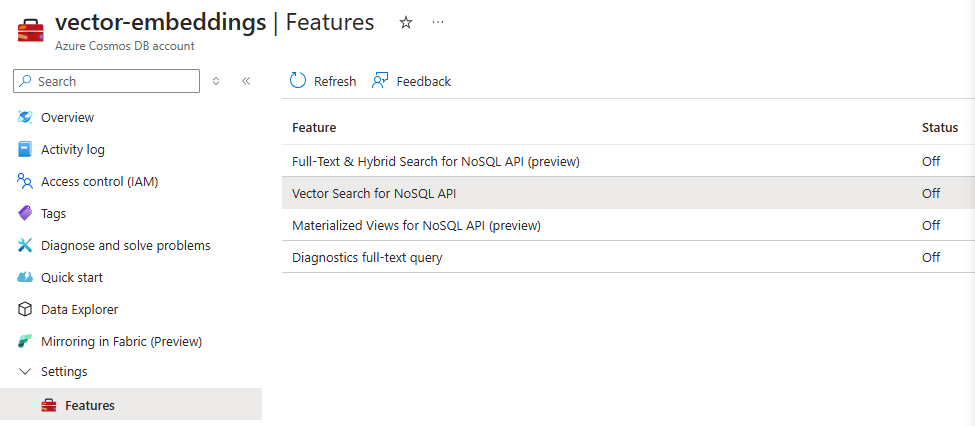
Next you need to create a container with a vector policy.
Note! Currently, vector policies in Cosmos DB are immutable, meaning that you can’t change the policy after the container has been created. If you need to change it, you must create a new container with a new vector policy, and migrate your data to the new container.
You define the vector policy on the same dialog where you create your container.
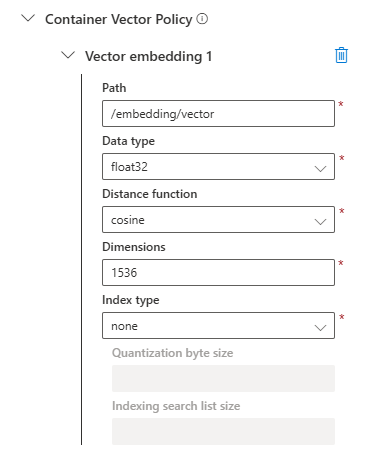
- Path: This is the path to the attribute on your JSON documents that contains the vector.
- Data type: The data type for the values in your vector. This value needs to match the data type your embedding model supports. Typically, embedding models create vectors containing floating-point numbers.
- Distance function: The function to use for calculating vector distance. A cosine function returns a value between -1 and +1 representing the similarity. A score of -1 is least similar and +1 is most similar.
- Dimensions: The number of dimensions of your vectors, i.e. items in the floating-point number array. You need to check the number of dimensions supported by the embedding model you plan to use.
- Index type: The index type to use. Read more about index types for Cosmos DB. With the index type, you can potentially decrease the the amount of Request Units (RUs) your vector queries consume, so be sure to check this out.
Generating Vectors with Embedding Models in Azure AI Foundry
There are many ways to generate vector embeddings. However, in this article I focus on generating them with the help of models deployed in Azure AI Foundry. You can use different kinds of SDKs to communicate with model deployments in Azure AI Foundry. I will not use any of those, but use simple REST calls to demonstrate how to communicate. I believe that this will give you the best understanding of how things actually work. It will then make it much easier for you to use an SDK or write your own, when you know how stuff works under the hood.
Provisioning the Required Azure Resources
To generate a vector, you need to provision an Azure OpenAI resource.
Then you need to deploy a model that is designed to be used for embeddings. There are several embedding models available. The text-embedding-3-small and text-embedding-3-large are probably the most recent models currently, at the time of writing (late Feb 2025).
I will use the text-embedding-3-small model in this example. It is much cheaper than its larger counterpart. However, you can pick any model that is capable of creating vector embeddings from text. Note that there are also embedding models that can create vector embeddings from images. Those models are out of the scope of this article. I’ll have to come back to those in a later article.
Creating the HTTP Requests
After you have deployed your embedding model, for instance the text-embedding-3-small, select the deployed model to open the Details page for the deployment.

On the Details page, copy the Target URI and Key to use when sending requests. All requests to this endpoint are POST requests with the key added to the api-key request header. In Postman, you can create one collection and define the authorization settings on the collection level. This way, all requests in that collection will inherit the same settings. The Postman settings are below.
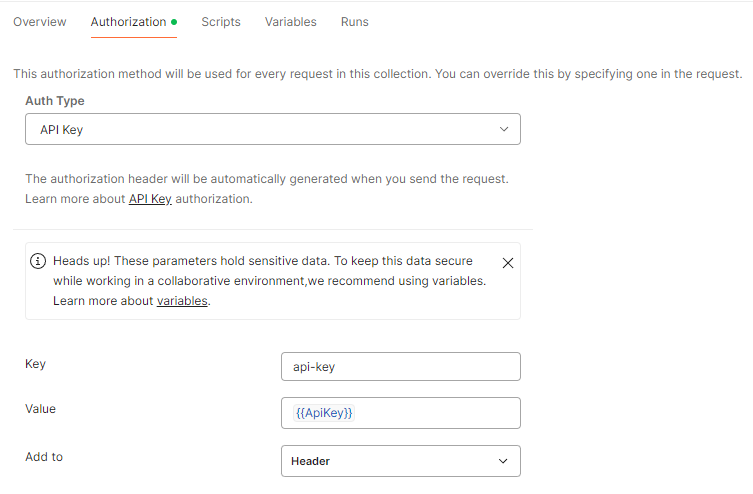
The request body looks like this.
{
"input": "Your text to generate the vector embedding for."
}
You can also specify specify multiple input strings by setting the input attribute to an array of strings, like this:
{
"input": [
"This is your first string.",
"The second string to generate vector embeddings for."
]
}
When you specify multiple input strings, you will also get the same amount of vector embeddings in the response. With embedding models like text-embedding-3-small and text-embedding-3-large, you can also specify the number of dimensions you want in the resulting vector embedding. The number of dimensions are specified in the request body as shown below.
{
"input": "My name is Bond. James Bond.",
"dimensions": 1024
}
For the text-embedding-3-small model, the minimum number of dimensions is 1, and the maximum number is 1536. For text-embedding-3-large, the minimum number of dimensions is also 1, but the maximum number is 3072. The more dimensions you have, the better you can capture different nuances in the input text. On the other hand, larger vectors take up more storage space in Cosmos DB and consume more Request Units when you query for data.
Note! Currently, there is a limitation for how long the input can be. Unfortunately there is no absolute limit that you could easily check before you send the request. Instead, the limit is expressed in tokens. The maximum input tokens for text-embedding-3-small and text-embedding-3-large are 8191 tokens. How many tokens that are consumed by a given text depends on many factors, such as language, text complexity etc. In general, a fair estimate for standard English text is that around 4 characters consume 1 token. This means that in theory, you should be able to generate vector embeddings as described above for a text containing 32 764 characters. Some text can be longer and some text can be shorter.
There are various patterns you can employ to generate vectors for larger text. I’ve written about the weighted average pattern in a previous article Vector Embeddings for Long Documents.
Storing the Generated Vector for Cosmos DB Vector Search
When sending the request as described above, you will get a response that looks like this.
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
0.006165823,
0.013940725,
-0.066804506,
0.015688516,
// ...
0.056068067,
0.036370724,
-0.0026667705,
-0.008225721
]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 8,
"total_tokens": 8
}
}
This response message is pretty self-explanatory. If you created your Cosmos DB container and vector policy as above, then you would probably store this vector in your container using a JSON document similar to the following.
{
"id": "5b39d118-65b6-46f4-a402-95c54b9e2648",
"partition": "partition-1",
"content": {
"text": "My name is Bond. James Bond."
},
"embedding": {
"vector": [
0.006165823,
0.013940725,
-0.066804506,
0.015688516,
// ...
0.056068067,
0.036370724,
-0.0026667705,
-0.008225721
],
"totalTokens": 8
}
}
Since this is a completely normal JSON document stored in a completely normal Cosmos DB container, you can of course add whatever data you think you need to store in this document. This can be anything you need to be able to effectively query the data later on.
Querying Data in Cosmos DB Vector Search
When querying your data using Cosmos DB Vector Search, you pretty much build your SQL query just as you normally would, with a few distinct differences.
- You use the built-in
VectorDistancefunction to order your results - You must always specify
SELECT TOP nto limit the number of items returned in the result
The VectorDistance function compares a given vector to the vector of each document matching the filters of the query. The result is then ordered so that the documents with the vectors closest to the vector specified in the query are listed first. The sample SQL query below uses the @queryVector parameter as placeholder for the vector.
SELECT TOP 5 c.id,c.partition,c.content, VectorDistance(c.embedding.vector, @queryVector) AS distance FROM c WHERE c.distance >= 0.8 order by VectorDistance(c.embedding.vector, @queryVector)
This query would return 5 JSON documents where the embedding vector is closest to your query vector. This means that the content in the resulting JSON documents is semantically most similar to the text that you used to generate the query vector.
The WHERE clause will further filter out the result to include only those documents that are actually similar to the query vector. This is to make sure that the result actually contains content similar to the query and not just something that is most similar even though not even close to what you are looking for.
Imagine that you have a container only containing documents describing various car models. Now, if you would query the container for recipes on deserts with bananas, you would get 5 documents describing car models. They are not similar at all to what you were looking for, but are the closest ones when there are no desert recipes in your container.
Filtering on Similarity
There is no exact description for what the values returned by the VectorDistance function actually mean, but you can use the following for some kind of basis for your decisions. If you are using the Cosine function as your distance function, the VectorDistance function returns a floating-point number between -1 and +1. -1 means no similarity at all, and +1 means very similar, if not even identical.
- +0.80 to +1: Very similar. These results are highly relevant and closely match your query.
- +0.50 to +0.79: Moderately similar. These results are somewhat relevant but may not be exact matches.
- 0 to +0.49: Low similarity. These results are not very relevant to your query.
- Below 0: Not similar. These results are quite dissimilar to your query.
Remember that what is considered “similar enough” can vary depending on your specific use case and context. Setting the similarity filter to +0.80 or above ensures that the result contains only highly relevant documents. I would suggest that you would run some tests with your content vectors and match them to expected query vectors to get the similarity filter to best suit your needs.
Practical Examples of Using Cosmos DB Vector Search
So what would you use the Cosmos DB Vector Search for? Why bother? Why not just use the vector indexes provided in Azure AI Search or Azure AI Foundry? Well, one thing for sure is that you have more control over what content is included in your query results. You also have control over how you generate vector embeddings for your content. If you have long documents, you could also split the documents into smaller parts like paragraphs or chapters, and generate vector embeddings for each part separately.
And you don’t have to settle for just searching for content similar to your query vector. You can add whatever filters you need to find the right content. Remember, that you are executing normal Cosmos DB SQL queries. In the chapters below I outline a few practical examples where you can leverage Cosmos DB Vector Search, some of which I have been working on, or will be working on myself.
Customer Knowledge Base
Let’s say you have a customer extranet that your customers log in to. On this extranet you have a lot of guidance and instructions related to the services that you offer your customers. But not all of your customers subscribe to the same services. Some of the instructions you publish are irrelevant to many of your customers. You might even have customer specific instructions that are relevant only to one customer and its representants.
With Cosmos DB Vector Search you could easily create vector embeddings for your instructions as shown in this article. You would then store these vectors in your Cosmos DB container along with information about what or which services each document is related to, or it it is related to just one particular customer. Then when your customers want to find something, you create a query vector from the customer’s search prompt and use that to find the most relevant instructions. You would also add more filters to include only instructions that are relevant to the customer and the services it subscribes to.
Suggest Similar Products or Content
Imagine you have an online store with a bunch of products. Your product information along with the product description is stored in a Cosmos DB container. You would also store the vector embedding for the product description with the rest of the product information.
Now when a visitor views a product, you could take the vector embedding for that product and find other products in your Cosmos DB container that are similar to the viewed product. The product being viewed would of course be the most similar, so you would need to filter out that particular product from the query results. Since you are running a standard Cosmos DB SQL query, that would be quite simple.
This same approach can be useful also for suggesting any type of content that is similar to for instance what is currently being viewed in an application. Take the previous example of a Customer Knowledge Base. When you display one instruction document, you could also offer other similar instructions, again filtering on the services the logged in customer is subscribed to.
Process Survey Responses
If you are in the business of doing surveys, you might find yourself in a situation where you are overwhelmed with the amount of responses. You might struggle with properly processing each response separately.
In some cases, you might be able to process responses in groups. To find these groups you might want to try to find similar responses, and then process the most similar responses in batches.
Document Classification
Some times you might have systems that store a lot of documents, and you need to categorize and classify these. Then you could pick one uncategorized document and categorize it manually. With the help of Cosmos DB Vector Search you find similar documents with the document that you categorized manually, and then categorize the most similar documents the same way you categorized the first document manually.
Multi-lingual Services
Since vector embeddings can be language agnostic, you could offer multi-language RAG solutions, without having to publish content in multiple languages. You could allow your users to give their prompts in whatever language they want, and create a vector embedding (query vector) from that. Then query the most similar documents using the query vector, and use the resulting documents as input to a chat completion model that would use the given documents to provide a response to the original prompt, and in the same language as that prompt. Of course, you would have to make sure that the embedding model you choose properly handles and supports multiple languages.
If you would like to display the documents returned by the similarity query, you could use a translation service to translate the original document into the language that the original user prompt was written in. You could also try to use a chat completion model to do the translation. Optionally, you could store that translation for future use so that you would not have to use a translation service every time.
How Much Does It Cost
So what does it cost to generate vector embeddings? That depends on the embedding model you use. I will use the text-embedding-3-small and text-embedding-3-large embedding models as example.
Remember that I talked about tokens above. The pricing for generating vector embeddings is also based on how many tokens you consume. The prices below (at the time of writing on late Feb 2025) are for 1000 tokens.
- text-embedding-3-small: 0.000020 EUR/1000 tokens
- text-embedding-3-large: 0.000125 EUR/1000 tokens
If we take the maximum number of tokens both of these embedding models support, 8191 tokens, and estimate that to a text of the length of 32 764 characters, it would incur the following costs with both of these models.
- text-embedding-3-small: 0.000164 EUR -> 0.0164 cents
- text-embedding-3-large: 0.00102 EUR -> 0.102 cents
Both of these costs are clearly peanuts, so we need to add more volume to the sample. Let’s assume that you have 10 000 documents that are all the maximum size supported by the embedding models, the cost for generating vector embeddings for all of those documents with each of the models would then be.
- text-embedding-3-small: 1,64 EUR
- text-embedding-3-large: 10,24 EUR
Still a pretty manageable cost, even for personal use I would say.
Conclusion and Further Reading
I hope that this article has given you at least some new information about what Cosmos DB Vector Search is, and what you might use it for. I believe that it is good to have options to choose from when designing solutions to tackle various problems. Of course, the more options you have, the more likely you are also to pick an option that is perhaps not the optimal for a particular case. The more you know and understand about the options you have, the better decisions you can make.
The following links provide you with further reading to get more information for even better decisions.


0 Comments