Things You Need to Know Before Building Applications With Azure Cosmos DB

If you’ve followed me on Twitter or GitHub, you probably have noticed that I’m quite a fan of Azure Cosmos DB. Over that last couple of years that I’ve been building applications with Cosmos DB, I’ve learned a few things that I wish I would have known in advance. Some of these are very hard, if not impossible, to change afterwards. This post is about these things.
This post also works as a summary for my Getting Started With Azure Cosmos DB tutorial on GitHub.
Partitioning
Partitioning is apparently becoming more of a non-issue what comes to things you should know before starting with Cosmos DB. In a previous post I wrote about something I noticed the other day. Basically, you can no longer create fixed containers on the Azure Portal.
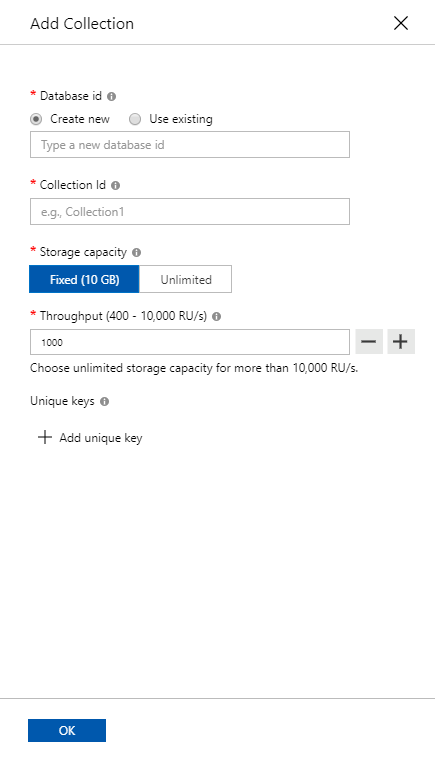
As the time of writing (early September 2019), you can still create fixed collections in the local Cosmos DB emulator. Click the picture to see more details. However, please do not create fixed collections. Not even locally! If you write your application for fixed collections, there’s a big chance that you will face refactoring, as I wrote in a previous post. Start building your applications from the start with partitioning in mind. It will save you time later on.
Partition Key
With the fact that all your containers will be partitioned comes the requirement of defining a partition key.
The partition key defines the path to the attribute in all your JSON documents that contain the value that identifies the partition the document will be stored in. Documents with the same value in this attribute are stored in the same partition.
The thing is that you should try to define a partition key that will result in an even distribution of data across all your partitions. This can be pretty hard, and sometimes even impossible. And even worse, one partition key can start producing different distribution over time.
The only help I can give you in addition to this is: Do your best, and learn from your mistakes, if you don’t get it right the first time around. I most certainly did not!
One technique that you can use to tackle the impact of the changing nature of your partition key is to use what’s called a synthetic partition key, which I talk about in the Data Model section below, and my Cosmos DB tutorial.
Sharing Throughput
Throughput is the amount of data that Cosmos DB can return in a set amount of time. This is measured as Request Units per second, or RU/s.
You can read more about RU/s in my tutorial on GitHub, so I’ll just add the definition for RU/s for your reference.
It “costs” 1 RU to read a 1 kB document, and 5 RUs to write a 1 kB document.
Even if it is pretty easy to arrange your collections later on, especially if you have designed your partitioning properly in the first place, it still is worth spending a few thoughts on throughput considerations.
There are two ways that you define the throughput for your containers:
- Specify for each collection separately
- Create a database with shared throughput and share it across all collections in that database.
If you have a collection for which you want to guarantee that it can provide you with the specified throughput, then go with option 1. Otherwise I would say that the second option is the way I would go by default.
Throughput Limits
In databases with shared throughput, the minimum is 400 RU/s. The same minimum applies also to collections with individual throughput configuration. However, on databases with shared throughput, there is also a minimum of 100 RU/s / collection. This means that if your database contains 1-4 collections, the minimum is 400 RU/s. If you have more collections, the minimum is 100 RU/s / collection. So for instance, if you have 15 collections in a database with shared throughput, the minimum that you can configure is 1500 RU/s for that database.
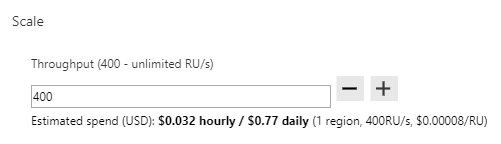
Please also note that there is no upper limit for throughput in Cosmos DB, except for your credit limit on your credit card, as you can see from the picture above. The same applies to both database with shared throughput as well as separate collections.
Data Model
You can definitely use the Cosmos DB SDK and access your data as generic JSON documents. I would not do that though. You will end up with a lot of magic strings in your code when trying to reference various attributes in your documents.
A better option is to create a class library that defines classes that represent different kinds of documents that you will be storing in your containers. Create one base class that all other document types inherit from, either directly or indirectly.
At a minimum, this base document type should define the following properties.
- Id: string
- Partition: string
- DocumentType: string
Even though the DocumenType property is not absolutely required, it will help you run your queries when you start storing different types of documents in the database.
I’m not going to go into deeper detail about this base class or building your class library. I’ve covered all of my thoughts in part 3 of my Cosmos DB tutorial: Designing a Data Model.
Conclusion
There’s of course a lot more about Cosmos DB than just partitioning, throughput and data modelling that you need to know in order to build applications for Azure Cosmos DB, but those are things you can learn as you go. The Cosmos DB documentation is an excellent resource to check every now and then.
Happy developing!
0 Comments